关于环境
本文的爬虫部分基于Python3.6,而Scrapy框架默认支持Python2,对于Python3需要手动安装:
- Twisted
- Lxml
- pywin32
从Scrapy新建项目、中途需要各种第三方库到最后的Scrapy执行爬虫、后文搜索引擎打造,都需要熟悉自己的环境变量(python、pip等版本),并善用python3 -m命令指定Python版本。
本项目所有操作在Windows10这个不友好的开发环境上完成,因此涉及到各种服务的启停、shell进入时需要手动定位可执行文件,并在正确目录下执行命令。
实现功能
- 利用Scrapy框架和Xpath解析网页信息并抓取
- Scrapy-redis实现分布式
- 分页抓取并存储到Mongodb数据库
- 使用Crawlera和随机UA突破反爬
- 通过elasticsearch同步Mongodb打造搜索引擎
本文最重要的部分是Mongodb直接同步Elasticsearch打造搜索引擎的内容,是互联网中文资料的纠错和整合,因此我把它提到了第一部分。
通过elasticsearch同步Mongodb打造搜索引擎
elasticsearch简介
elasticsearch是java开发的一个基于lucene的搜索服务器,分布式多用户的全文搜索引擎, 基于restful web接口。
elasticsearch基础概念:
- 集群:一个或多个节点组织在一起。
- 节点:一个集群中的一台服务器。
- 分片:索引划分为多份的能力,允许水平分割,扩展容量,多个分片响应请求。
- 副本:分片的一份或多分,一个节点失败,其他节点顶上。
对应关系:
es | 数据库
—|—
index | 数据库
type | 表
document | 行
fields | 列
elasticsearch配置
使用elasticsearch的中文发行版elasticsearch-rtf,已经集成了大量需要用到的插件,而elasticsearch官网版缺少很多插件。
配置elasticsearch.yml:
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-methods: OPTIONS,HEAD,GET,POST,PUT,DELETE
http.cors.allow-headers: "X-Requested-With,Content-Type,Content-Length,X-User"
配置好后执行elasticsearch.bat,服务映射在本地9200端口。

还需额外安装插件:
用于管理数据库,基于浏览器。
npm run start启动服务,映射在本地9100端口。
npm install可能由于源的问题安装失败,推荐淘宝NPM镜像cnpm。
执行npm install -g cnpm --registry=https://registry.npm.taobao.org后,将所有npm命令换为cnpm。

(编辑elasticsearch.yml后从elasticsearch-head连接,集群健康值代表连接成功。)
Kibana需要和head的版本对应。
执行/bin目录下的kibana.bat启动服务,映射在本地5601端口。
连接Mongodb数据库:
- Mongodb开启副本集
#首先停止Mongodb服务(很重要)
#自己设定数据集所在目录
cd
mkdir dumps && cd dumps
mkdir rs0
#切换到mongo目录
cd /usr/bin
#从mongod设置副本集rs0
mongod --dbpath "/home/yutaotao/dumps/rs0" --replSet "rs0"
#在Mongo shell中初始化
rs.initiate()
- 利用mongo-connector连接
安装mongo-connector、elastic-doc-manager(注意这里不是下划线)。
在上一步中保持mongo服务运行,开启elasticsearch服务,执行:
mongo-connector -m 127.0.0.1:27017 -t 127.0.0.1:9200 -d elastic_doc_manager
即可连接mongo和es,此后对Mongodb的增删改查都将同步到elasticsearch。
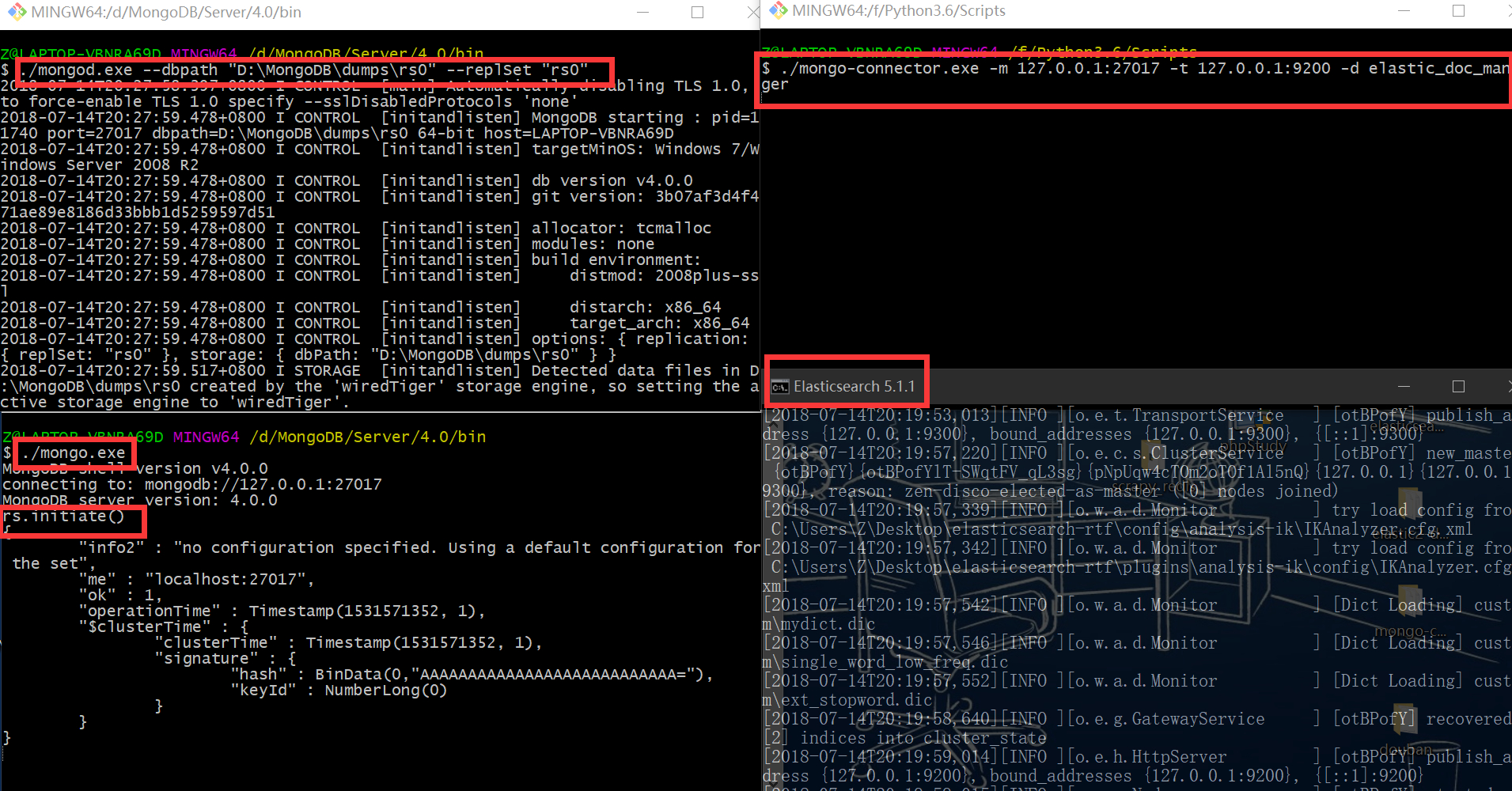
注意看我的命令,Windows下我做了许多细微的调整。
接下来重新爬取并存储Mongodb:
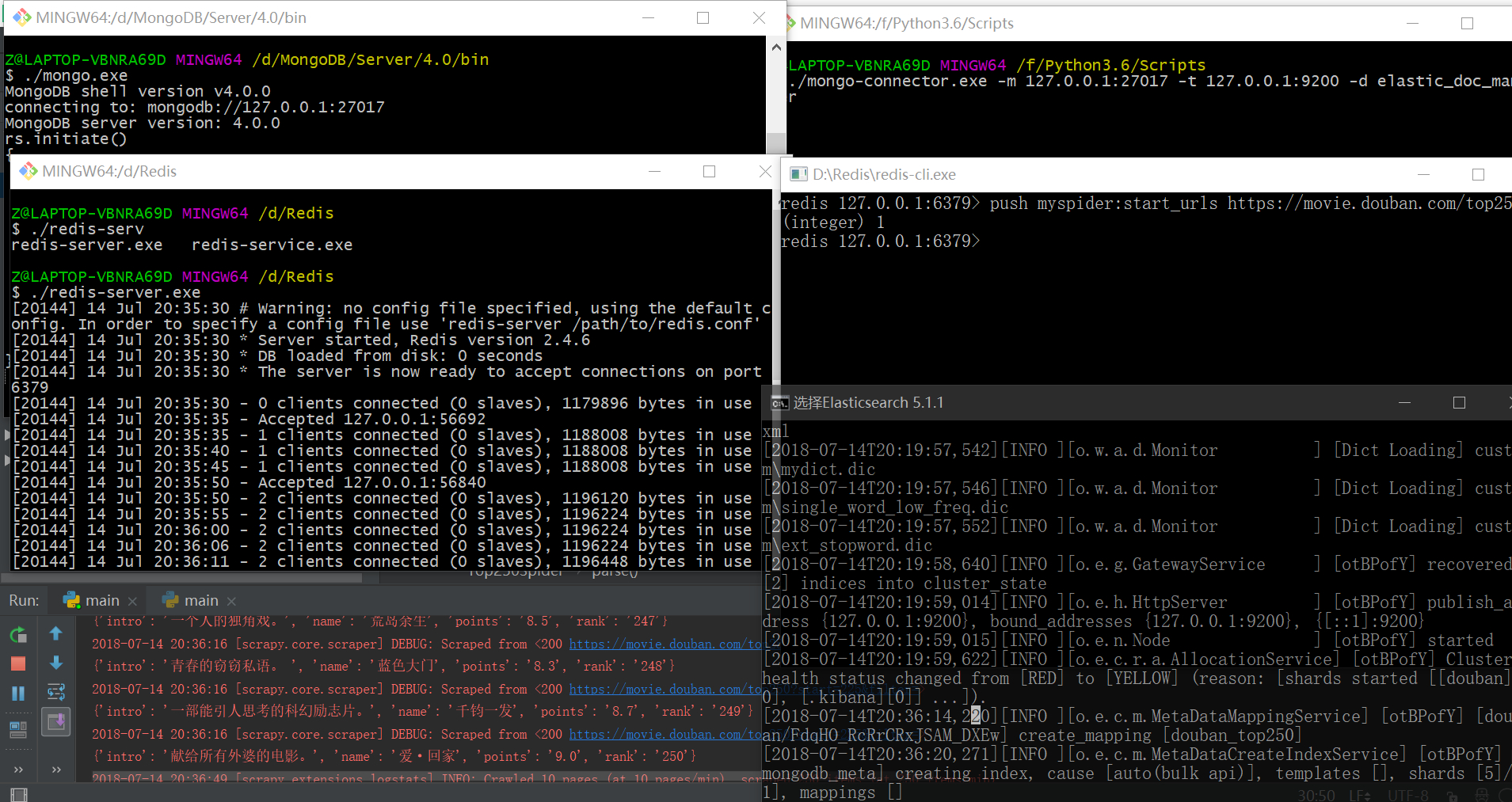
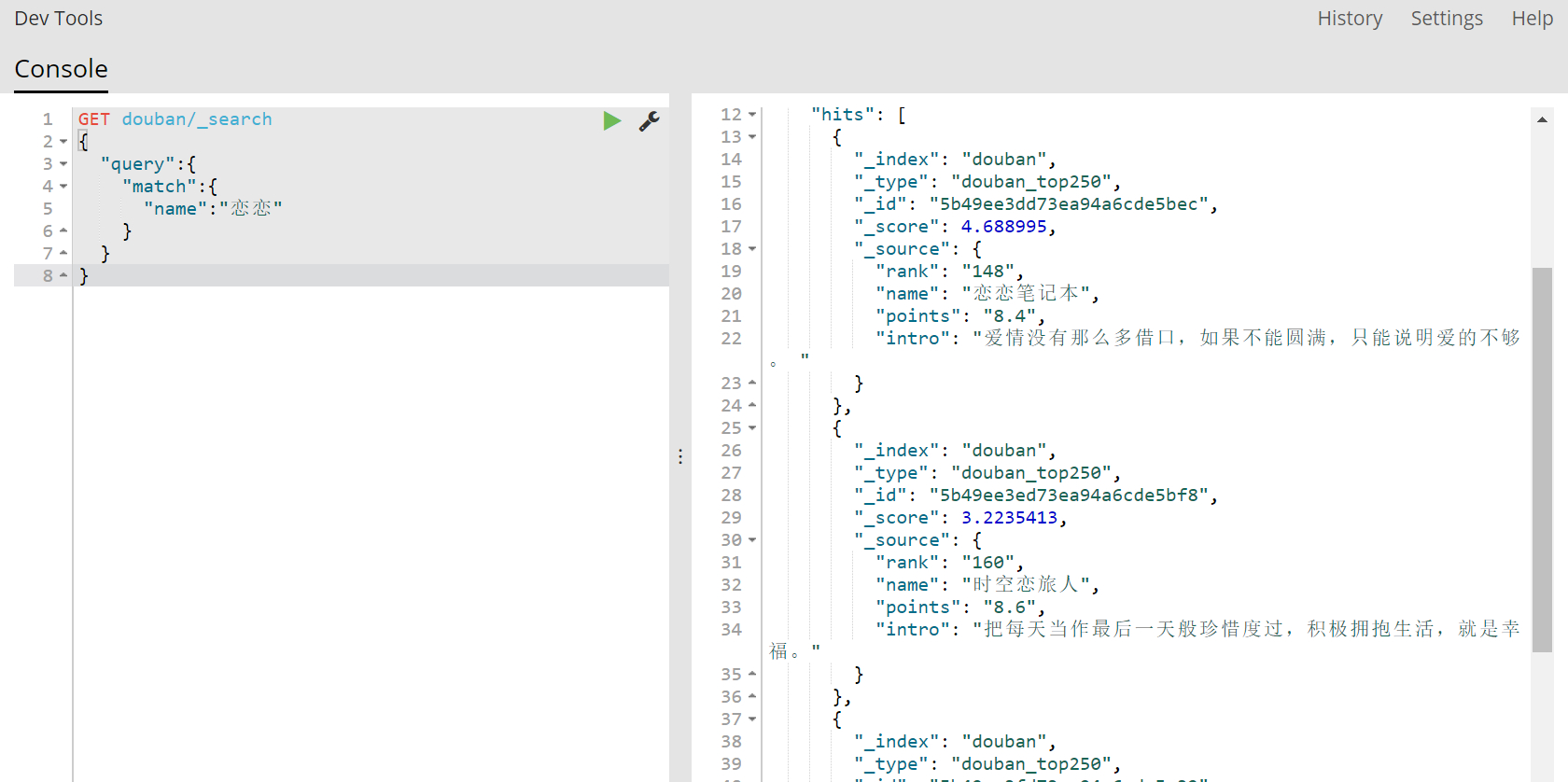
查看elasticsearch:

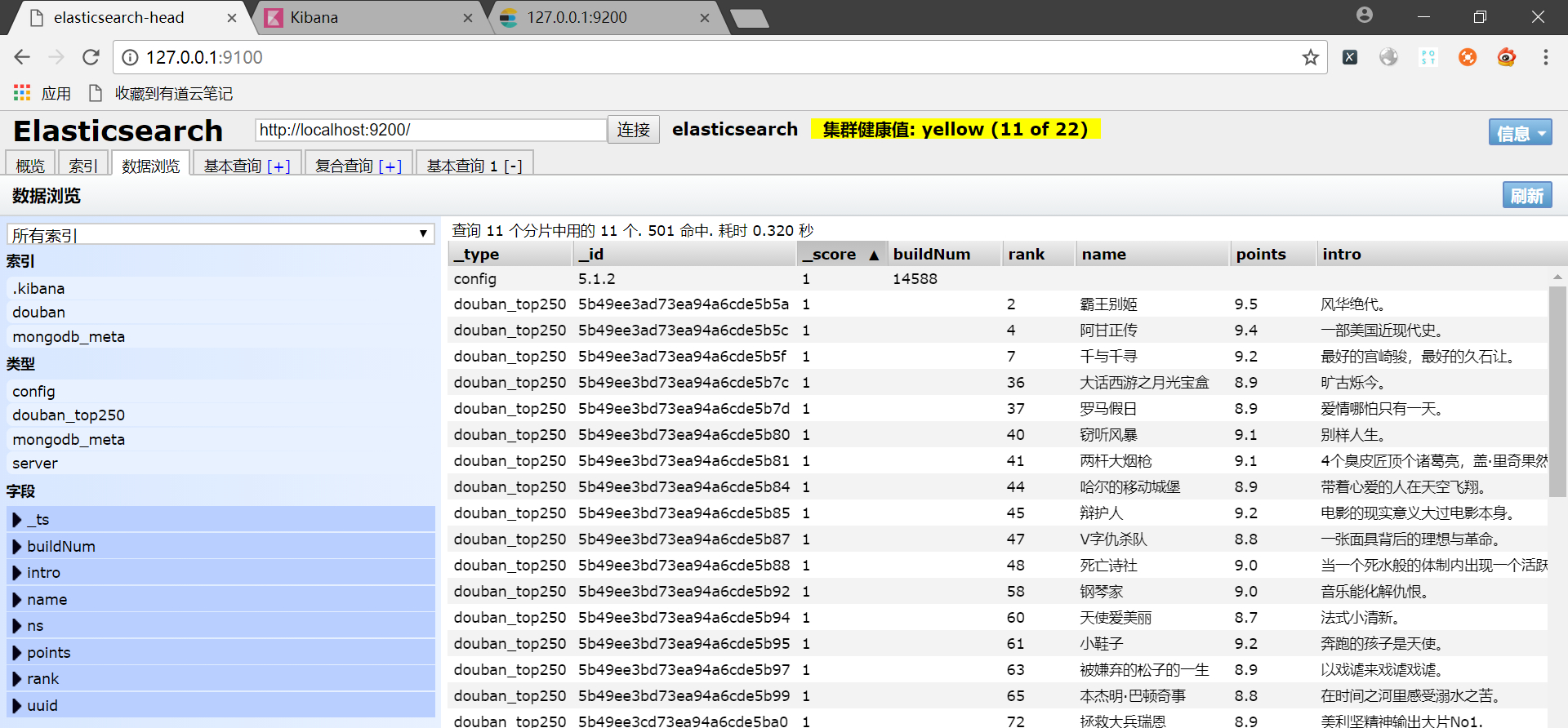
索引建立成功了!鸡冻!!
这一部分我经过了漫长的调试和排错,每重试一次都要开上十个不同地方的shell一步一步输命令…如果在Linux下会好很多。
elasticsearch此时已经自动建立了mapping映射:

查看数据:

通过Kibana的命令行已经可以实现搜索,用_search方法:
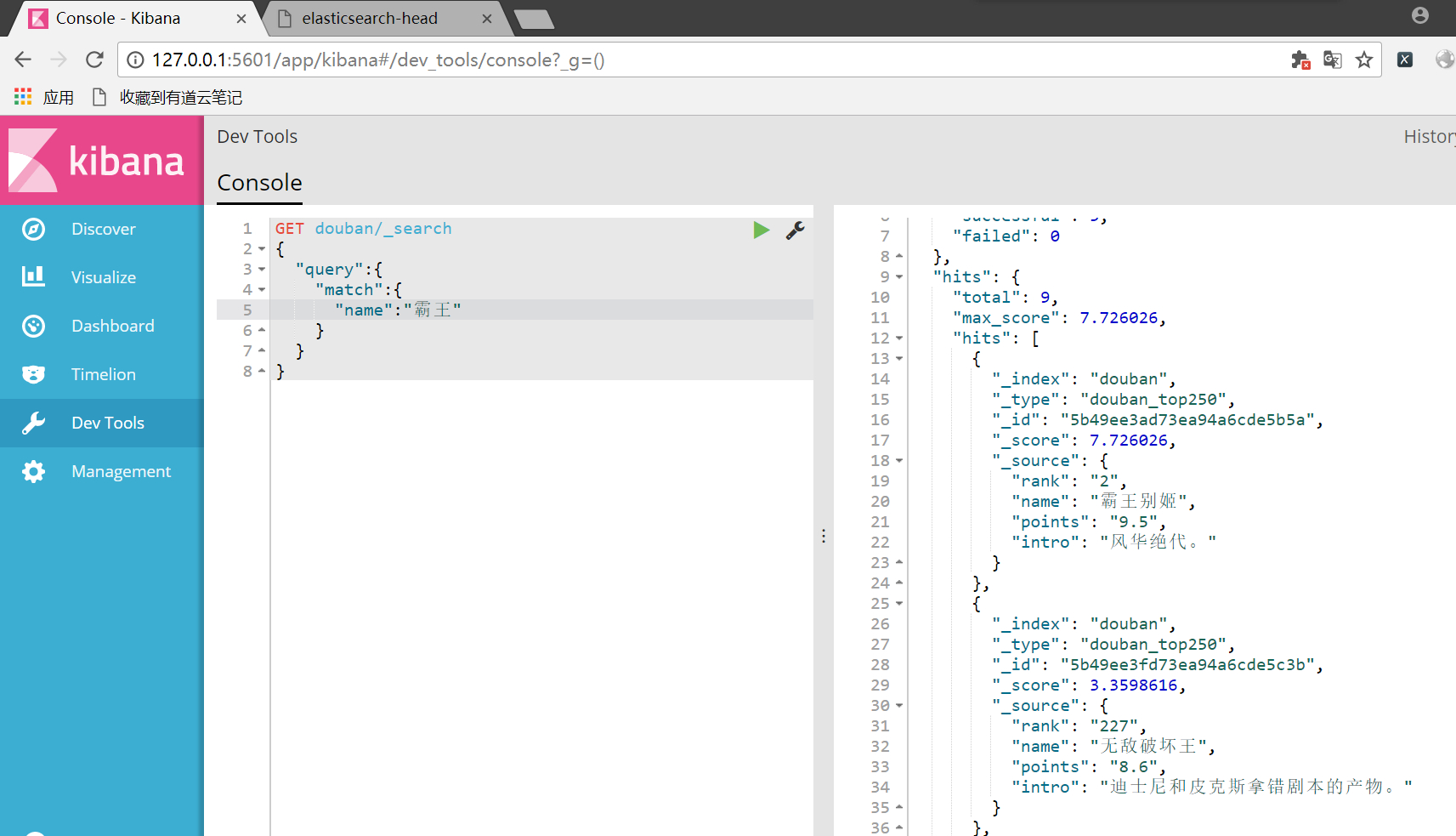
可以看出来还是比较智能的,已经实现了中文分词。
利用Scrapy框架和Xpath解析网页信息并抓取
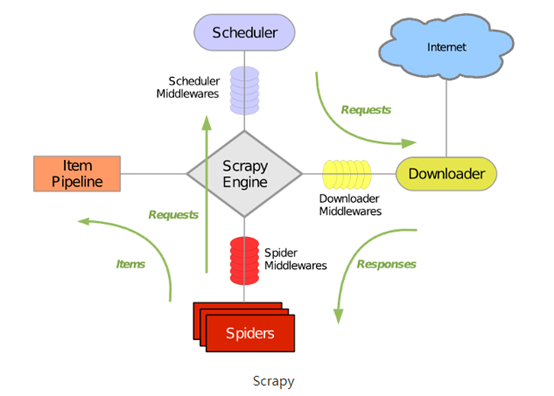
scrapy中文文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
Scrapy整体架构图:
直接爬取25页结果:
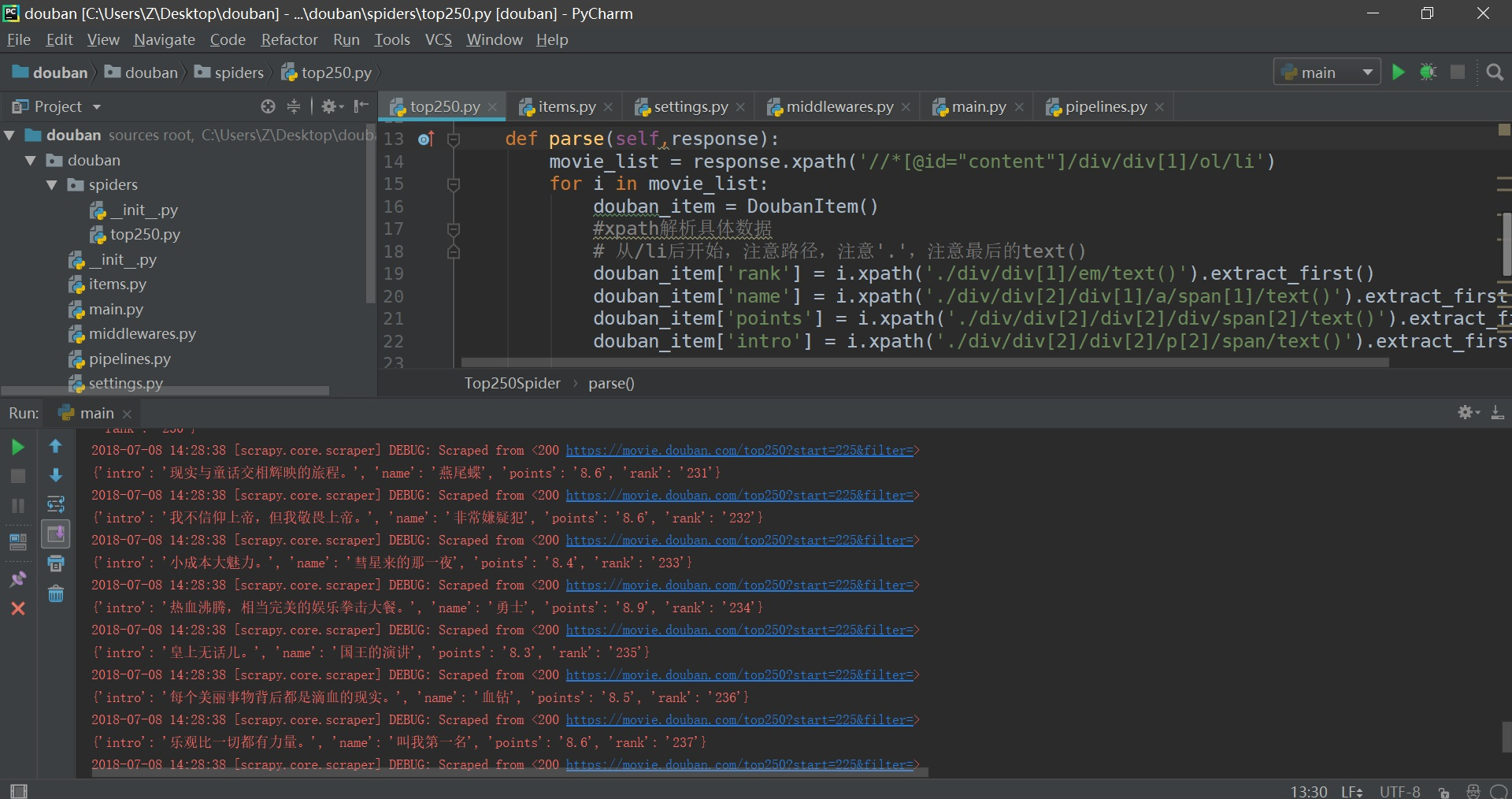
(DEBUG:200可能是由于js的解析问题,其实已经成功爬取。)
scrapy-redis实现分布式
使用redis数据库来替换scrapy原本使用的队列结构(deque)
scrapy-redis提供了Scheduler、Dupefilter、Pipeline、Spider组件。对于已有的scrapy程序扩展成分布式程序:
找一台高性能服务器,用于redis队列的维护以及数据的存储。扩展scrapy程序,让其通过服务器的redis来获取start_urls,并改写pipeline里数据存储部分,把存储地址改为服务器地址。
分布式原理:
scrapy-redis实现分布式,其实从原理上来说很简单,这里为描述方便,我们把自己的核心服务器称为master,而把用于跑爬虫程序的机器称为slave。我们知道,采用scrapy框架抓取网页,我们需要首先给定它一些start_urls,爬虫首先访问start_urls里面的url,再根据我们的具体逻辑,对里面的元素、或者是其他的二级、三级页面进行抓取。而要实现分布式,我们只需要在这个starts_urls里面做文章就行了。
我们在master上搭建一个redis数据库(注意这个数据库只用作url的存储,不关心爬取的具体数据,不要和后面的mongodb或者mysql混淆),并对每一个需要爬取的网站类型,都开辟一个单独的列表字段。通过设置slave上scrapy-redis获取url的地址为master地址。这样的结果就是,尽管有多个slave,然而大家获取url的地方只有一个,那就是服务器master上的redis数据库。
并且,由于scrapy-redis自身的队列机制,slave获取的链接不会相互冲突。这样各个slave在完成抓取任务之后,再把获取的结果汇总到服务器上(这时的数据存储不再在是redis,而是mongodb或者 mysql等存放具体内容的数据库了)。
这种方法的还有好处就是程序移植性强,只要处理好路径问题,把slave上的程序移植到另一台机器上运行,基本上就是复制粘贴的事情。
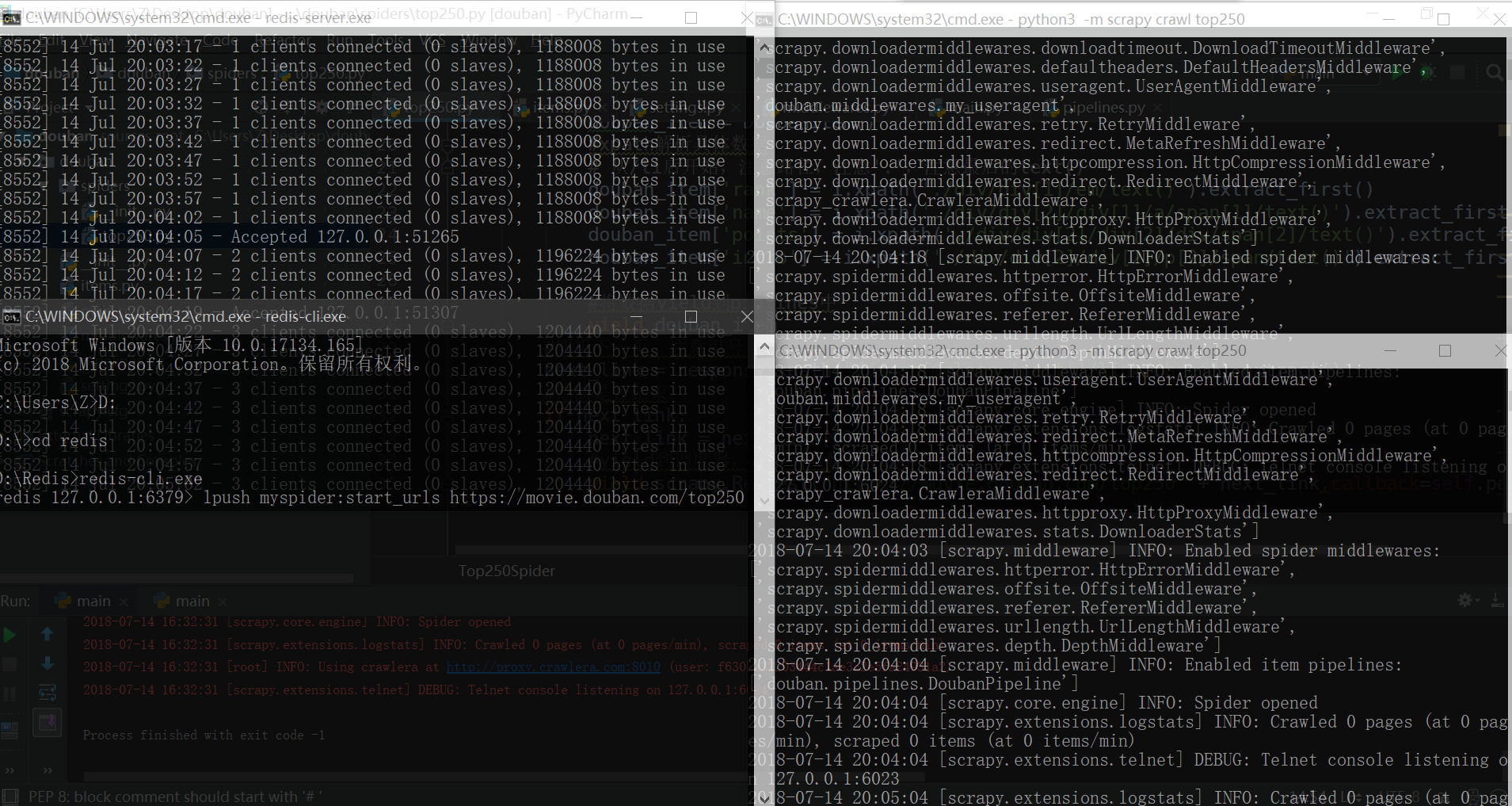
改写爬虫文件后,执行scrapy crawl top250时不再爬取数据,而是处于监听状态。
启用redis服务并在redis-cli中添加start url,则爬虫开始多进程执行。
lpush myspider:start_urls https://movie.douban.com/top250
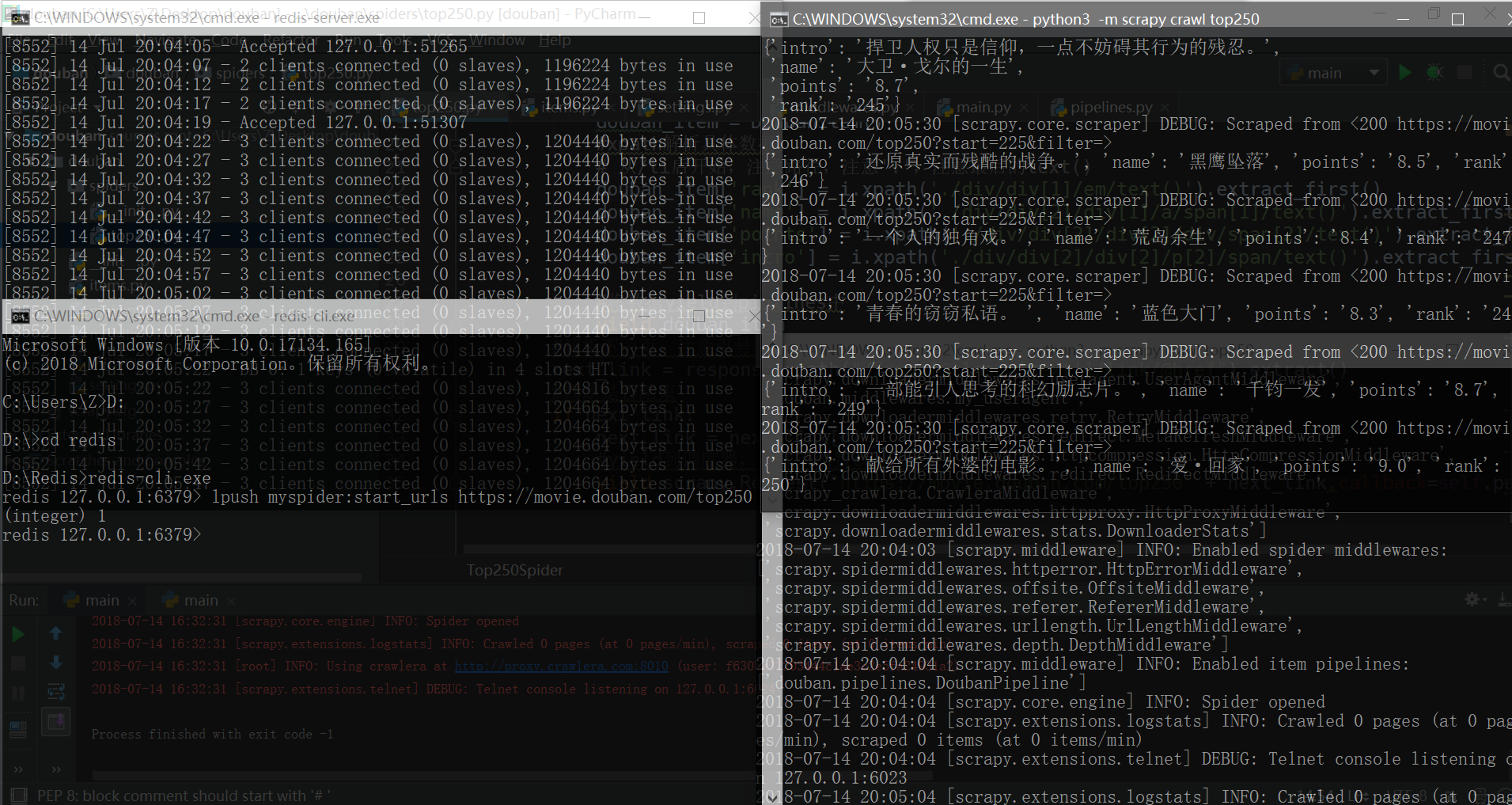
此处的演示为伪-分布式,如果在多机器执行则为分布式。
分页抓取并存储到Mongodb数据库
在不连接数据库的情况下,数据存储也很方便,Scrapy提供了直接的数据导出功能,可以添加-o参数,将结果导出到csv、json文件。
这里为练习数据库操作直接存储到数据库。使用pymongo库后在scrapy中只需要简单的配置:
class DoubanPipeline(object):
#连接 Mongodb
def __init__(self):
host = mongo_host
port = mongo_port
dbname = mongo_db_name
sheetname = mongo_db_collection
client = pymongo.MongoClient(host=host,port=port)
mydb = client[dbname]
self.post = mydb[sheetname]
对于Mongodb这个nosql数据库我使用了NoSQL Manager for MongoDB进行管理。
(此处是玄学之字体重叠)
shell中的查询操作也很简单:
use douban
show collections;
db.douban_top250.find()
db.douban_top250.find().pretty()
使用Crawlera和随机UA突破反爬
Crawlera
crawlera是一个利用代理IP地址池来做分布式下载的第三方平台。
crawlera官方网址:http://scrapinghub.com/crawlera
crawlera帮助文档:http://doc.scrapinghub.com/crawlera.html
使用介绍:https://www.cnblogs.com/rwxwsblog/p/4582127.html
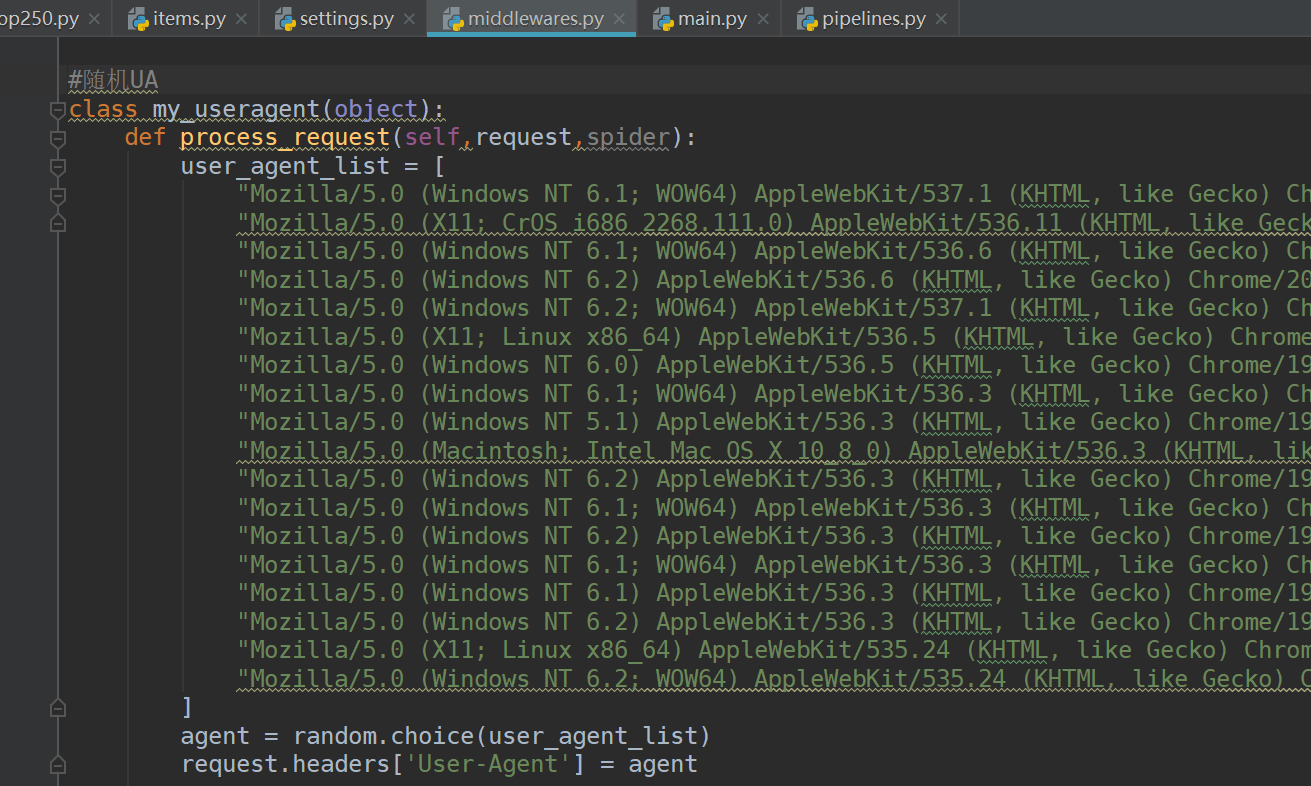
随机UA
后记
这是一个为期6天的开发项目。多亏Python爬虫领域已经有完善的资料供搜查,让我这个开发小白体会到更多的是乐趣而不是困难。